p-mvsnet阅读
2021-03-27
-
from Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation Hongwei Yi PKU
-
pmvs 同样是 mvsnet 系列的网络。mvsnet 从 Yao Yao 开始,逐步成为了 2020 年的热点研究方向。 引言提到了他们的 Vamvsnet(没有引用也没有搜到)。PMVS 是一种金字塔结构,能够自适应的聚集不同视角的视图,以前基于 MVS 的深度学习方法使用均方差的方式生成代价量。他的方法使用两种新的方法 Pixel-Wise View 和 Voxel-Wise Views 聚合不同的视图。实验通过 DTU 数据集训练出结果,并且生成结果能够和 T&T 数据集上的方法具有相当的表现
- 最近的方法可以几乎不通过立体匹配取解决匹配的歧义性(Deepmvs: Learningmulti-view stereopsis. In: CVPR (2018)Dpsnet: End-to-end deep plane sweep stereo.)他们遵循所有视角获取的视图再代价量空间中有同样的贡献。例如 MVSnet 和 RMVSnet 再多个视角的代价量空间上使用了均方差的操作。而 DPSnet 使用了均方值操作。然而视图的不同之处在于不同的照明条件(DTU)相机外参,场景的变量。作者使用自适应融合模块可以更好的增强匹配的区域,抑制不匹配的区域(?)
- 第二,多尺度信息没有利用,ACMM(Xu, Q., Tao, W.: Multi-scale geometric consistency guided multi-view stereo)逐步处理递归获取由粗到精细的深度图。他通过多尺度将金字塔的不同尺度的深度图并行聚合起来生成精细深度图
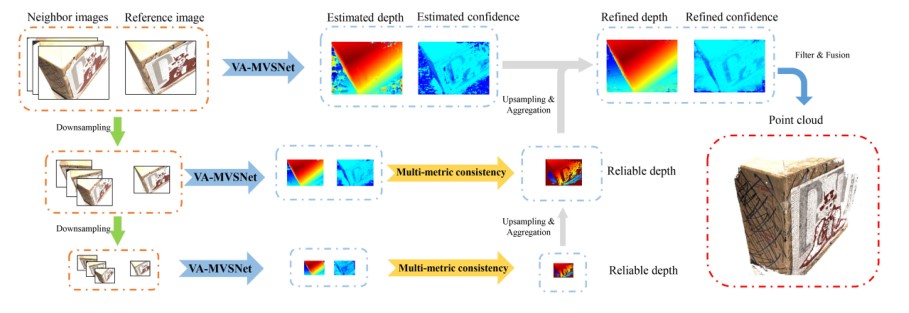
- 具体过程 设置好每一组图片中的参考视图以及参考视图临近的视图,分别用 i=0 和 i=1,2…n 表示 n 表示多视图图像的数量。如图对 n 个图像使用 k 个下采样层构成 K-Level 图像金字塔,k=0 表示原始图像
- 下一步是 VAMVSnet(有点模仿 MVSnet?)
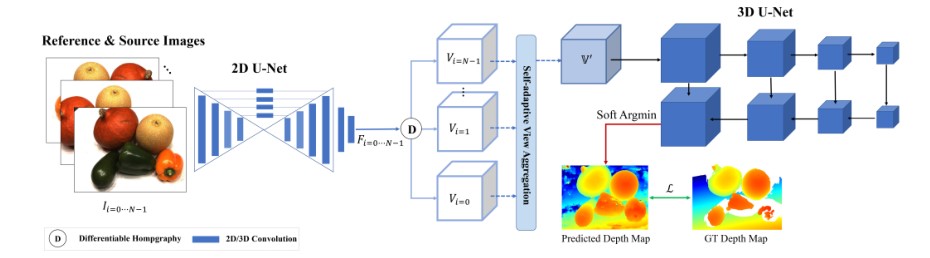 MVSnet 是特征提取,单应,U 型金字塔,深度估计(几层 conv)
它先是 N 支用来接收图像,U 型金字塔,(特征得到后 1/4 下采样),然后使用差分单应变换,将其他源视图对应到参考视图的对应点位,目的是将每一组对应的特征点位进行合并,将 W,H,D,C 的特征空间变成 W,H,D,C(C 为一组对应点 Vi=V0,V1,V2….)。以前的工作对输入的特征空间求均方差,作者觉得不够合理,被遮挡的图像内容和相机位置应该被去除,没有遮挡的视图可以提供更加准确的几何和光学信息所以作者使用了自适应视图聚合模块。总共费为两种不同的逐像素的视图聚合模块 Pixel-Wise View 和 Voxel-Wise Views 。Pixel-Wise View 类似 ACMM。 Voxel-Wise Views 模块是一种使用 3D 注意力机制 3D 特征空间中的每个体素来学习自身的权重。
Pixel-Wise View
和均值相似,PWV 方法使用一种将卷积空间加权相加后求均值的操作。每一个视图的卷积空间 v 在减除参考视图的卷积空间以后得到的结果 v’。w+1 代表每个视图的卷积空间需要逐元素相乘的权重。其中 w 可以通过 PA-Net 求得。PANet 由 ConvGR(对 ground true 还是参考视图进行卷积?),ResBlockGR(一个 Resnet 的模块),一个卷积层,一个 sigmoid 层组成(其中 sigmoid 层实现了非线性),PAnet 将各个视图的结果分别进行最大池化和平均池化操作,从而提取最大和平均成本匹配信息,最后使用 concat 串联起来作为输入。 Voxel-Wise Views 认为不同深度层 D 的像素需要不一样的处理。所以和 PAnet 不同,VAnet 主要使用 3d 卷积包括两个 3d 卷积,3DGR,conv3d 最后通过一个 sigmoid’层实现。和 MVSnet 一样,作者使用 L1 损失函数也就是绝对差值作为损失。
作者使用 dtu 数据集,也就是长宽为 640 和 512,设置输入的图像为 5,也就是每一次训练的图像包括 5 个不同的视点获得的视图。深度估计主要是从 425mm 到 935mm 间,分为 192 个深度平面,以 2.5mm 作为不同平面的差值。作者使用 pytorch,在学习率为 0.001 的情况下训练了 16 个 epoch,decay0.9 每个 epoch。设置 batchsize 为 4,在 4 个 titanx sli 的主机上运行进行训练。测试时输入的图像数为 7,dtu 测试的数据集为 1600 _ 1184(为啥我的是 1600 _ 1200)。测试 Tank 和 Temple 时输入的图片相似为 1920 * 1080,使用 openmvg 获取相机参数
MVSnet 是特征提取,单应,U 型金字塔,深度估计(几层 conv)
它先是 N 支用来接收图像,U 型金字塔,(特征得到后 1/4 下采样),然后使用差分单应变换,将其他源视图对应到参考视图的对应点位,目的是将每一组对应的特征点位进行合并,将 W,H,D,C 的特征空间变成 W,H,D,C(C 为一组对应点 Vi=V0,V1,V2….)。以前的工作对输入的特征空间求均方差,作者觉得不够合理,被遮挡的图像内容和相机位置应该被去除,没有遮挡的视图可以提供更加准确的几何和光学信息所以作者使用了自适应视图聚合模块。总共费为两种不同的逐像素的视图聚合模块 Pixel-Wise View 和 Voxel-Wise Views 。Pixel-Wise View 类似 ACMM。 Voxel-Wise Views 模块是一种使用 3D 注意力机制 3D 特征空间中的每个体素来学习自身的权重。
Pixel-Wise View
和均值相似,PWV 方法使用一种将卷积空间加权相加后求均值的操作。每一个视图的卷积空间 v 在减除参考视图的卷积空间以后得到的结果 v’。w+1 代表每个视图的卷积空间需要逐元素相乘的权重。其中 w 可以通过 PA-Net 求得。PANet 由 ConvGR(对 ground true 还是参考视图进行卷积?),ResBlockGR(一个 Resnet 的模块),一个卷积层,一个 sigmoid 层组成(其中 sigmoid 层实现了非线性),PAnet 将各个视图的结果分别进行最大池化和平均池化操作,从而提取最大和平均成本匹配信息,最后使用 concat 串联起来作为输入。 Voxel-Wise Views 认为不同深度层 D 的像素需要不一样的处理。所以和 PAnet 不同,VAnet 主要使用 3d 卷积包括两个 3d 卷积,3DGR,conv3d 最后通过一个 sigmoid’层实现。和 MVSnet 一样,作者使用 L1 损失函数也就是绝对差值作为损失。
作者使用 dtu 数据集,也就是长宽为 640 和 512,设置输入的图像为 5,也就是每一次训练的图像包括 5 个不同的视点获得的视图。深度估计主要是从 425mm 到 935mm 间,分为 192 个深度平面,以 2.5mm 作为不同平面的差值。作者使用 pytorch,在学习率为 0.001 的情况下训练了 16 个 epoch,decay0.9 每个 epoch。设置 batchsize 为 4,在 4 个 titanx sli 的主机上运行进行训练。测试时输入的图像数为 7,dtu 测试的数据集为 1600 _ 1184(为啥我的是 1600 _ 1200)。测试 Tank 和 Temple 时输入的图片相似为 1920 * 1080,使用 openmvg 获取相机参数