UCSNet论文阅读
2021-03-28
UCSNet 论文阅读
平面扫描法
- 平面扫面算法将深度范围内分为一个个平面,平行平面足够密集,空间被分割的足够细,空间物体表面上的一点 M 一定位于平行平面中的其中一个平面上。又有另一个点 M’,假定这个点也在这个平面上,但是它不位于任何可见物体的表面上,这样的点很有可能投影到每个可见摄像机上,并不是同样的颜色
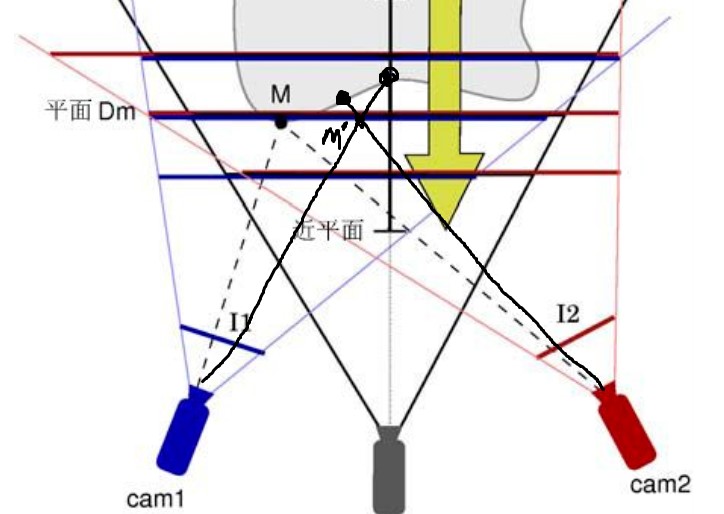
- 单应矩阵就是通过线代的方法通过矩阵表示不同视角的相机平面对应点的关系(2D-》3D-》2D)。主要的部分有内参矩阵和外参矩阵(也可以单分为平移旋转),内参矩阵记录相机的参数,外参矩阵主要由物点和相机的空间关系决定。例如参考图像上的一点和原图像的对应点可以表示为 x’=Hx(x 为参考图像),H 时 Homograph 的缩写,也就是单应矩阵。
- 损失函数也就是 cost function,由于上面的原因,所以不能只利用两点颜色相同来匹配对应点,需要利用每个点的窗口信息,因此需要在两个窗口每个对应像素求得绝对差然后镜像求和,由于时多视点因此还需要对多个源视点和参考视点获得的视图进行上述操作然后求和,其中可以对源视图添加计算光照变化的增益因子。计算出来的 loss function 取最小值就是对应视图中的对应点。
UCSnet
-
以前的方法依赖于平面空间扫描,PSV,并且对每一个深度平面有着固定的深度假设,但是这样的前提是密集的对平面采样并且需要很高的精度,然而由于内存有限,高分辨率的深度几乎是不切实际的。作者提出了 ATV(adaptive thin volume)自适应薄空间扫描(volume 空间)。在一个 ATV 中,每一个深度片面的深度假设都在变化。UCSnet 有三个阶段,第一个阶段将小的 PSV 估计成为低像素的深度,两个 ATV 在下面得阶段将深度优化为具有更高像素和更高精确度的深度。作者的 ATV 只包含少量的平面且只占用较低的显存和计算资源。同时他在碰到小的无法确定的间隔(interval)情况下,能有效地划分局部的深度范围。它计划使用基于方差的不确定性估计去自适应的构造 ATV;这种可分的操作更加合理和精细的空间分区。我们的多阶段的框架逐步的将庞大的场景空间使用越来越高分辨率和精度逐步划分为,这样使得高完整度和高精确性的重建可以由粗糙到精细的方式实现。
-
推断 3D 场景在 3D 可视化,在场景理解,机器人和自主驾驶多有应用。最近在 MVS 上的成功是 3d 卷积在平面空间扫描上的应用,这能够又凶啊的推断多视图的对应点。然而 3d 卷积为了提到准确率和完成度涉及到大量的显存使用,这一点,尤其表现在处理大场景或者高精确度和高完整性的需要采样大量的扫描平面或者是需要重建高像素的深度图的各种场景中。总之,在给定限定的显存的情况下,先前的工作中在精确度(更多平面)和完整性(更多像素)的权衡中没有任何有希望的尝试。作者的目标时实现在低内存和消耗的同时实现高准确率和完整性的重建。
-
作者使用多个效地卷积空间,而不是大的标准的平面空间扫描,实现从粗到精的递归求出高质量的深度,关键在于使用 ATV 实现有效的空间分区。
作者先是对 3d 重建的空间表示做了分类,包括基于体素,基于光锥(可以把他放入体素的结构里),另一些使用形状先验(shape prior(那种白色前景黑色背景的掩模图?GB 和 BB?))不能直接应用到大尺度的场景重建。现在的一些方法尝试直接构建表面网络 surfacemesh,可变形状 deformable shape,并且通过一些隐式的距离函数学习,这些基于表面重建的方法看起来比基于点云重建的方法要顺利,但是他们会缺乏细节信息。
作者肯定了深度推断在三维重建中的重要性,不管在单目相机还是多目相机中都有应用。传统的 MVS 方法流程依赖于光一致性约束,但是常常由于无纹理区域和遮挡区域以及复杂的光照环境表现很差。克服了这些问题的方法就是基于深度学习的 MVS 方法,作者对基于学习的 MVS 方法进行了分类,基于回归的方法(多个尺度多个深度平面),以及基于分类的方法(?,基于循环递归结构(最典型的 RMVSnet)的方法,这些方法按照均匀采样的深度推断使用 2d 或者 3d 卷积构造了一个代价空间去推断最终的深度,然而显存成了瓶颈。RMVSnet 循环神经网络在处理代价空间时使用了大量的采样平面(512,然鹅这种方法仅仅使用较少的采样空间(104。有提到 PointMVS 将粗造的重构,通过学习的方法细化。,然而它使用自适应薄体积扫描 ATV(一个电视)来细化深度,比 pointmvs 效果更好(point2019,这 2020 的)。
-
具体网络结构为
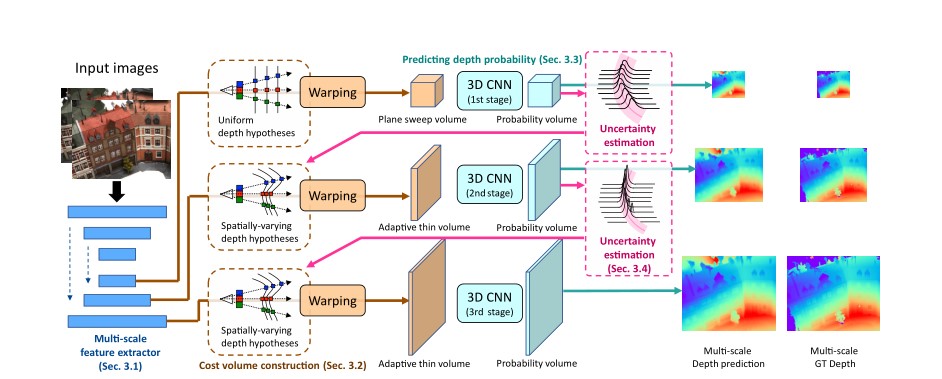
1.提取三种分辨率的深度特征图。 2.构建平面扫描空间和 ATV 自适应薄空间,每一个空间时两者之一。
- 使用 3D 卷积预测深度分布,根据结果重建深度图。 4.构建 atv 作为最后两个阶段的代价量 5.multistage 从粗糙到精细的方式有效的重建
1.特征提取
- 以前的方法使用下采样层或者是 Unet 提取特征,并且在单一像素大小下建造一个平面扫描空间。作者的特征提取模块时一个效地 2D uNet,在编码器和解码器的对应层有着跳层链接。编码器结构包括一系列卷积层+bn+relu,stride 步长设置为 2,这样可以每次下采样时原来图像大小的 1/2。解码器是由上采样层和跳跃连接的连接特征组成。在解码器的最后提取三个不同尺度的特征图。F1,F2,F3,分别为 1/4,1/2,1 的大小,通道数分别为为 32,16,8。
2.代价空间构建
-
在多个尺度构建多个代价空间构建的方法时将三个提取的特征图 Fi,1,Fi,2,Fi,3 ,分别代表第 i 个视角提取的第几阶视图。从源视图单应变换到参考视图。其中单应矩阵为 4*4 的矩阵,可以表示为
-
Hi(d) = KiTiTi’Ki’
-
每一个代价空间有多个平面组成,用 Lk,j 表示第 k 阶(例如上文的特征提取提出 1/4,1/2,1 三阶)第 j 个平面的深度假设, Lk,j (x)代表在像素 x 上的值。一旦使用对应点的假设 Lkj,作者计算对应点弯折的每一个视图输出的特征图的方差构建代价空间。使用 Dk 代表第 k 阶平面的数量。第一个阶段,它使用标准的平面空间扫描,深度估计时常(不变的)数。例如 L1,j(x) = dj。使用 L1,j 从[dmin,dmax]间均匀取样(psv),第二阶和第三阶使用了 ATV,他们的深度假设根据像素的不确定性估计具有在空间变化的深度值。
3.深度预测和可能性分布
- 每一部分使用 3D 卷积层 来处理代价量,推断多视图对应和预测深度概率分布。整体结构是一个 3d Unet,在 Unet 的末尾使用 softmax 来预测逐像素深度概率。Lk,j 代表深度估计,Pk,j 时每像素的深度可能性分布,其中 Pk,j 代表了 xiangsux 处于 Lk,j(x)的可能性通过对 Lk,j 乘以 P 作为权重的求和得到深度图 Lk。
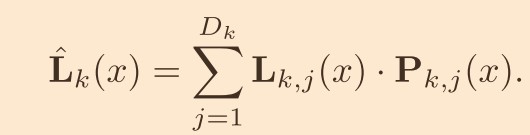 (2)
(2)
4.不确定性估计和 ATV(电视)
- 新的 ATV 是随着空间变化的深度平面,具有弯曲的深度平面。上一步利用像素分布的期望(也就是公式 2)来估计深度。这里使用基于方差的不确定性估计并且构造 ATV。
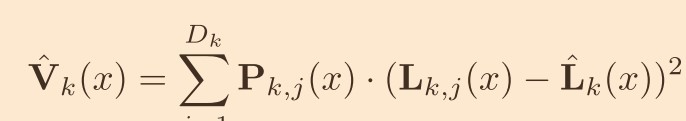 标准差为上式的根号。
标准差为上式的根号。 - 在获得 Lk(公式 2)和他的标准差(即上市的根号),作者使用基于方差的置信区间来衡量深度预测的不确定性,如下式
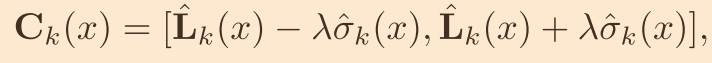 其中 λ 是一个定好的参数,决定置信区间的大小。
其中 λ 是一个定好的参数,决定置信区间的大小。 - 对于每一个在 k 阶的像素 x,将置信区间使用均匀采样分为 Dk+1 个深度值,获取 Lk+1,1(x),Lk+1,2(x)……Lk+1,Dk+1(x)作为 K+1 个子阶的深度,于是在每一个均匀采样的深度平面间有构造了 Dk+1 个深度平面的建设,形成了 ATV 的 k+1 阶
- 置信度区间 Ck(x)表示预测的深度值的 Lk(x)的不确定区间。Ck 本质上描述了地面真值表面周围的概率局部空间,地面真值深度位于不确定区间内,置信度一般最高。由于 UCSnet 可威风,所以 ATV 可以自己调整调整不确定的深度图估计。
实验
- 使用 DTU 数据集训练和测试,训练三个阶段的端到端网络 60 个 epoch,使用 Adam 优化器,设置学习率为 0.0016。使用 8 个 1080ti,batchsize 设置为 16,每一个 GPU 设置 batchsize 为 2